最大規模單細胞擾動測序資料集,AI支持虛擬細胞研究
最大規模單細胞擾動測序資料集,AI支持虛擬細胞研究
2024 年 4 月,一家名為 Xaira Therapeutics 的人工智慧(AI)藥物研發公司成立,並同時宣佈獲得了令人瞠目結舌的 10 億美元種子輪融資。該公司致力於通過新興 AI 技術的端到端應用,幫助重新設計藥物的發現和開發之旅。
該公司擁有一個星光熠熠的創始和領導團隊,包括 AI 蛋白質設計先驅、2024 年諾貝爾化學獎得主 David Baker 教授,以及 2022 年諾貝爾化學獎得主 Carolyn Bertozzi 教授、美國 FDA 前局長 Scott Gottlieb、強生公司前 CEO Alex Gorsky,以及斯坦福大學前校長 Marc Tessier-Lavigne 等。因此,整個 AI 藥物研發領域都在熱切期待著該公司取得令人矚目的科學成果。
現在,這家 AI 獨角獸企業不負眾望,在其成立的第一年就為虛擬細胞(Virtual Cell)研究領域送上了一份厚禮——發佈了目前最大的公開可用的 Perturb-seq 資料集,名為 X-Atlas/Orion,為虛擬細胞研究提供支援,該資料集可用於 AI 模型訓練,並能檢測劑量依賴性遺傳效應,從而增強藥物發現的預測能力。
該資料集於 2025 年 6 月 16 日發表在預印本平臺 bioRxiv,論文題為:X-Atlas/Orion: Genome-wide Perturb-seq Datasets via a Scalable Fix-Cryopreserve Platform for Training Dose-Dependent Biological Foundation Models。
根據論文中的介紹,X-Atlas/Orion 包含了 8000000 個細胞,涵蓋了人類所有編碼蛋白質的基因,單細胞的深度測序超過 16000 個獨特分子識別字(UMI)。
Perturb-seq 是基於單細胞轉錄組測序(scRNA-seq)、以彙集的形式同時讀出單細胞的 CRISPR sgRNA 遺傳擾動和轉錄組的方法。過去,研究人員一直將 Perturb-seq 基因敲低視為一種“開”或“關”的開關,而 X-Atlas/Orion 通過檢測劑量依賴性遺傳效應取得了進步,從而揭示了基因活性如何隨著特定干預措施的強度而變化,例如,可應用於確定對藥物靶點的抑制百分比達到多少時會產生預期治療效果。

大規模平行測序技術的迅猛發展催生了基礎模型開發生態,這類模型可通過解析海量生物資料揭示全新生物學發現。然而,儘管 AI 驅動的虛擬細胞模型具備加速科學發現的革命性潛力,其發展始終受限於高品質擾動資料的規模性短缺——這一困境源于資料生成過程的可擴展性瓶頸與實驗方法變異性的雙重制約。
該研究推出了創新性的“固定–凍存–單細胞測序”(Fix-Cryopreserve-scRNAseq, FiCS)Perturb-seq 平臺,該工業化解決方案實現了擾動測序數據的規模生產。
實驗驗證表明,FiCS 平臺展現出卓越的檢測靈敏度與微弱的批次效應,能精准捕捉基因擾動引發的轉錄組變化,準確重現經典生物學通路與蛋白複合體特徵。作為技術示範,Xaira Therapeutics 正式發佈當前全球最大規模的公共擾動資料庫——X-Atlas/Orion。該資料集源自兩項針對人類全部蛋白質編碼基因的全基因組 FiCS Perturb-seq 實驗,包含 8000000 個深度測序細胞,單細胞獨特分子識別字(UMI)超 16000 個,為領域研究樹立新標杆。
該研究還揭示,sgRNA 豐度可作為基因敲低效能的有效表徵。通過深度測序與每次擾動條件下充足細胞量的技術優勢,證實基於 sgRNA 表達的劑量分層可解析遺傳效應的濃度依賴性特徵。
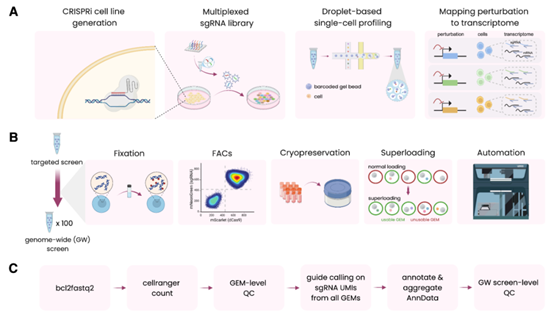
工業化 Perturb-seq 平臺工作流
綜合來看,FiCS Perturb-seq 成功打造了高效、可擴展的高通量擾動測序平臺。通過 X-Atlas/Orion 資料集的發佈,不僅為解決資料生成中的規模化和標準化難題提供關鍵方案,更將推動融合基因劑量效應的新一代基礎模型開發,為加速生命科學發現注入強勁動力。
為促進虛擬細胞研究領域的開放協作,X-Atlas/Orion 資料集將以非商業使用許可向生物技術界開放共用。對於有意開展商業合作的公司,Xaira Therapeutics 表示願意就資料授權與應用開發等合作模式進行商談。
對於傳統的早期藥物研發,通常僅限於從文獻中挑選少數幾個基因進行嘗試,但高性能的虛擬細胞(Virtual Cell)模型卻有可能在研發流程中不良生物學效應出現之前就將其排除。
許多虛擬細胞模型是基於觀察資料訓練的,例如 CZ CELLxGENE,其單細胞資料主要來自健康的人類捐贈者,雖然觀察資料對於某些生物學研究任務(例如細胞類型注釋)非常有用,但在預測細胞對擾動(例如藥物治療)的回應方面卻存在不足。
在 Perturb-seq 中,由於單細胞資料集的隨機性和稀疏性,測量基因敲低效率一直頗具挑戰性。為解決這一難題,Xaira Therapeutics 的研究人員證明,sgRNA 的豐度在每個細胞中能被檢測到並表達數百個拷貝,這在單細胞檢測中極為罕見,並且為基因被抑制的程度提供了一個可靠的替代指標。
除了 Xaira Therapeutics,還有多個機構致力於構建虛擬細胞,例如,陳-紮克伯格倡議(CZI)在今年 4 月份發佈了 Transcript Former,這是一種生成式 AI 模型,能夠跨物種探究細胞生物學,並具有治療應用。與此同時,Arc 研究所宣佈與 10x Genomics 和 Ultima Genomics 建立合作夥伴關係,共同構建 Arc 虛擬細胞圖譜。
像 X-Atlas/Orion 這樣大規模全基因組實驗可能極其耗時。僅對細胞進行分類以富集高品質細胞就可能需要超過 10 個小時。通過發佈 X-Atlas/Orion 的方法,Xaira Therapeutics 旨在讓更多的實驗室能夠以大規模、高品質和標準化的規模生成 Perturb-seq 資料,讓各個實驗室有能力利用大規模資料來檢驗特定假設。